Learning Word Embeddings with AWS Blazingtext
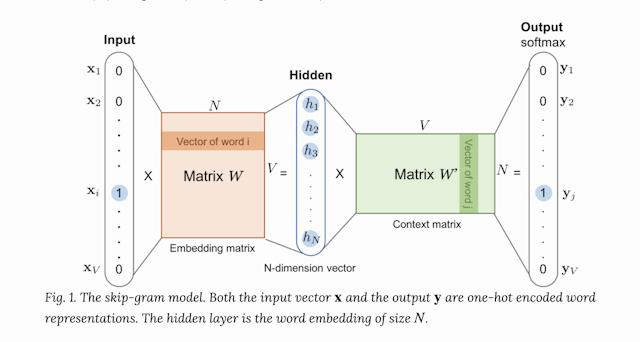
What is Word Embedding?
As we all know, Machine Learning algorithms deal with numbers and do not consume text directly. Previously, one way to consume text data was to use tfidf, count vectorizer, to convert text into numbers that ML Algorithms can consume. With the recent developments in NLP techniques, there is a new way to represent text-based on language semantics.
For example The ____ sat on the mat. If we were to fill in the blanks in the above example, most of us would fill it with Cat with options as (Cat, Air, Cloud, Donkey)
"You shall know a word by the company it keeps" (J. R. Firth)
The meaning of the word can be learned from the context in which the words appear. The topic was first introduced in the paper https://arxiv.org/pdf/1301.3781.pdf ( Mikolov et al.)
Word2Vec itself supports SkipGram and CBOW, and the details of which are explained clearly in the paper mentioned above. I also found out another blog which explains clearly about <Link href="https://lilianweng.github.io/lil-log/2017/10/15/learning-word-embedding.html" color="blue.500" fontWeight="bold"> how to learn word embedding </Link>
tl;dr
- CBOW: Predicts the word given a context
- SkipGram: Predicts the context given a word The Word2vec algorithm maps words to high-quality distributed vectors. The resulting vector representation of a word is called word embedding. In the embedding space, semantically similar words correspond to vectors that are close together. That way, word embeddings capture the semantic relationships between words.
There has been significant development in Word Embeddings, and there are many other word embedding algorithms like
- doc2vec (Le and Mikolov (2014))
- GloVe (Pennington, Socher, and Manning (2014))
- fastText (Bojanowski, Grave, Joulin, and Mikolov (2016))
- Latent semantic analysis (Deerwester, Dumais, Furnas, Harshman, Landauer, Lochbaum, and Streeter (1988))
- BERT (Devlin, Chang, Lee, and Toutanova (2018))
If you want to understand a bit more other text transformation techniques take a look at <Link href="https://shrikar.com/blog/word-embeddings-word2vec-and-latent-semantic-analysis" color="blue.500" fontWeight="bold">Word2Vec and LSA embeddings</Link>
AWS Sagemaker BlazingText Algorithm
In this blog post, we will be talking about AWS Sagemaker Blazing text, an improved version of the Word2Vec algorithm that also supports generating embeddings for subwords.
Generating word representations by assigning a distinct vector to each word has certain limitations. It cannot deal with out-of-vocabulary (OOV) words, that is, words that have not been seen during training. Typically, such words are set to the unknown (UNK) token and are assigned the same vector, which is an ineffective choice if the number of OOV words is large.
Blazing text algorithm has also adding featured for generating vectors for n-grams based on <Link href="https://arxiv.org/pdf/1607.04606.pdf" color="blue.500" fontWeight="bold"> Enriching Word Vectors with Subword Information</Link>
Applications of Word Embeddings
- Similar Entities. Entities, in this case, could be Search Queries, SEO Titles, Products, and more.
- Similar Search Queries: Let us say we are building a search engine for an e-commerce store. Having an understanding of similar searches can help guide users through their sessions.
- Retrieval Tasks. Let us say we are building an e-commerce search engine and want to retrieve candidates to re-rank. The embedding-based retrieval is a pretty good baseline. Feature to the downstream models like NER, Text Classification, and Ranking
BlazingText Example in python
Here is how to cleaned_dataset.csv looks like
keyword # header
seo analyzer
seo keyword research
...
...
Upload the file with search queries to "s3://bucketname/cleaned_dataset.csv" replace bucketname with your s3 bucket name.
Now let's look at some code that is boilerplate to setup sagemaker training jobs.
import sagemaker
from sagemaker import get_execution_role
import boto3
import json
import pandas as pd
import numpy as np
sess = sagemaker.Session()
role = get_execution_role()
print(role) # This is the role that SageMaker would use to leverage AWS resources (S3, CloudWatch) on your behalf
bucket = 'bucketname' # Replace with your own bucket name if needed
s3_train_data = "s3://bucketname/cleaned_dataset.csv" # Cleaned CSV in case of query similarity would be all the search queries
s3_output_location = "s3://bucketname/output/"
region_name = boto3.Session().region_name
container = sagemaker.amazon.amazon_estimator.image_uris.retrieve("blazingtext", region_name, "latest")
print("Using SageMaker BlazingText container: {} ({})".format(container, region_name))
AWS provide custom containers for algorithms that they provide making it super easy to run and scale a job.
bt_model = sagemaker.estimator.Estimator(container,
role,
instance_count=1,
instance_type='ml.c4.2xlarge', # Use of ml.p3.2xlarge is highly recommended for highest speed and cost efficiency
volume_size = 100,
max_run = 360000,
input_mode= 'File',
output_path=s3_output_location,
sagemaker_session=sess)
bt_model.set_hyperparameters(mode="skipgram",
epochs=20,
min_count=5,
sampling_threshold=0.0001,
learning_rate=0.05,
window_size=3,
vector_dim=100,
negative_samples=5,
subwords=True, # Enables learning of subword embeddings for OOV word vector generation
min_char=2, # min length of char ngrams
max_char=6, # max length of char ngrams
batch_size=11, # = (2*window_size + 1) (Preferred. Used only if mode is batch_skipgram)
evaluation=True)# Perform similarity evaluation on WS-353 dataset at the end of training
train_data = sagemaker.session.TrainingInput(s3_train_data, distribution='FullyReplicated',
content_type='text/plain', s3_data_type='S3Prefix')
data_channels = {'train': train_data}
bt_model.fit(inputs=data_channels, logs=True)
s3 = boto3.resource('s3')
key = bt_model.model_data[bt_model.model_data.find("/", 5)+1:]
s3.Bucket(bucket).download_file(key, 'model_dim_100.tar.gz')
!tar -xvf model_dim_100.tar.gz
vectors.bin
eval.json
vectors.txt
Let's look at what the above code is doing
- We are setting the instance_count to 1 and can be increased to higher number for distributed training. Along with the node count we provide the instance type to be used for training.
- Note the s3_output_location is where the model artifacts will be stored.
- For this example we are using the skipgram mode.
- In order to ensure the embeddings are meaningful we remove token that appear less than 5 timers
- Learning rate and sampling rate are hyper parameters that can be tuned
- 100 is the vector embeddings size.
- subwords = True ensure that we generate embedding for ngram as provided by the min_char and max_char
At this point in time you have the word/ngram embeddings that can be use by downstream tasks mentioned above.
Before we start consuming the vectors lets normalize the vectors as shown below.
import numpy as np
from sklearn.preprocessing import normalize
first_line = True
word_to_vec = {}
num_points = 106055
with open("vectors.txt","r") as f:
for line_num, line in enumerate(f):
if first_line:
dim = int(line.strip().split()[1])
word_vecs = np.zeros((num_points, dim), dtype=float)
first_line = False
continue
line = line.strip()
word = line.split()[0]
vec = word_vecs[line_num-1]
word_to_vec[word] = vec
try:
for index, vec_val in enumerate(line.split()[1:]):
vec[index] = float(vec_val)
except:
pass
# index_to_word.append(word)
if line_num >= num_points:
break
word_vecs = normalize(word_vecs, copy=False, return_norm=False)
Let's take the task of similar search queries. You might be wondering how we go about getting the vector representation for multi token queries. We can try different approaches like (average, min, max etc) but one common approach followed by the industry is to average the word vectors to get the representation for any entity vector(search query, product name etc)
Converting word to entity vector representation
df = pd.read_csv('cleaned_dataset.csv')
ids = range(0, len(search_terms))
search_terms = df.keyword.unique()
search_vec = [np.mean([word_to_vec[word] if word in word_to_vec else np.zeros(100) \
for word in str(x).split()] , axis=0) for x in search_terms]
data_dict = {'search_terms': search_terms, 'search_vectors': search_vec, 'ids': ids}
joblib.dump(data_dict, 'search_terms_vectors_dim_100.npy')
At this point we have a vector representation for each search query.
Approximate Near Neighbor Search using Embeddings
For ANN's (Approximate nearest Neighbor) search we have many libraries like faiss, annoy, scann etc. In this blog we will use annoy as it's the simplest to use and something that I have played around with before. In subsequent blog posts we will look into faiss/scann.
Let's start with building an annoy index.
from annoy import AnnoyIndex
f = 100
t = AnnoyIndex(f, 'euclidean') # Length of item vector that will be indexed
for i in range(len(search_vec)):
v = search_vec[i]
t.add_item(i, v)
t.build(10) # 10 trees
Now that the tree is built we will look into finding the nearest search queries given an input query.
import random
def similar_search(term=None, n = 20):
terms = []
if not term:
idx = random.randint(0, len(search_terms))
term = search_terms[idx]
for id in t.get_nns_by_item(idx, n):
terms.append(search_terms[id])
else:
idx = list(search_terms).index(term)
for id in t.get_nns_by_item(idx, n):
terms.append(search_terms[id])
return terms
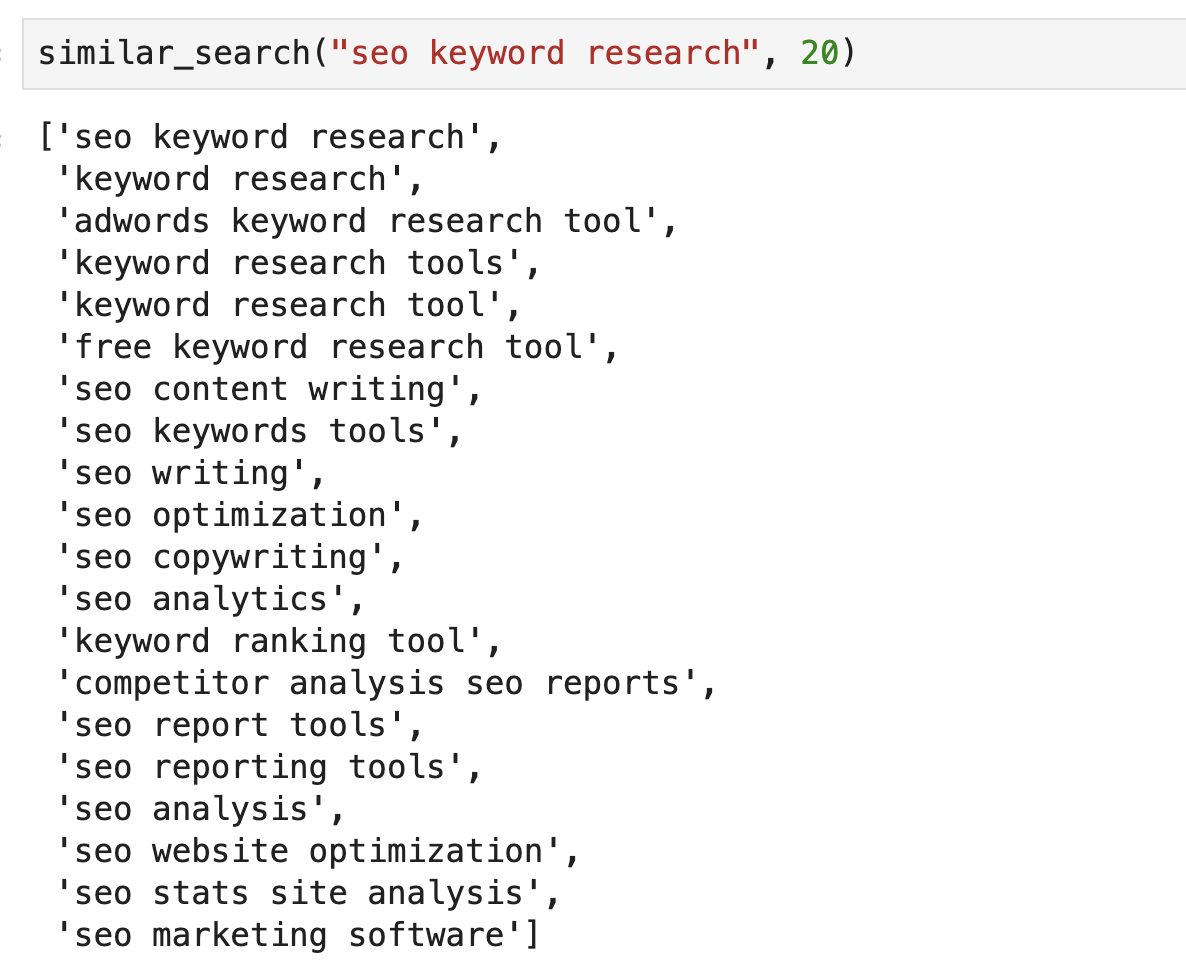
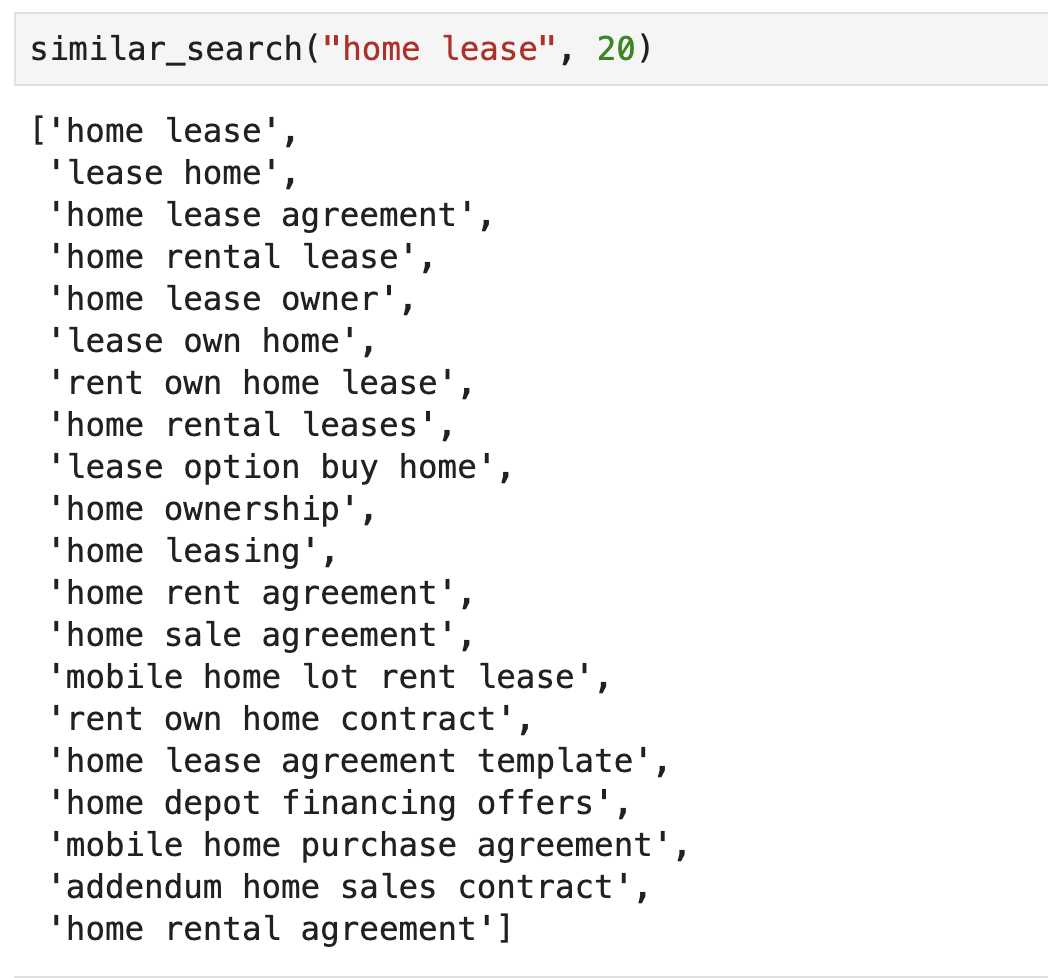
Let's look at some example to see how the algorithm worked.
Here are a few other useful posts that might be of interest to you.
- MultiClass Classification using Keras : Python Code for Multiclass classification
- PySpark Real time predictions
- AWS Serverless Lambda: Serverless Framework and AWS Lambda Tutorial
- Data mining Reddit for Travel Recommendations: Reddit Data Mining